Biomedical Image Segmentation - UNet++
Improve segmentation accuracy with a series of nested, dense skip pathways
In this article, we will be exploring UNet++: A Nested U-Net Architecture for Medical Image Segmentation written by Zhou et al. from the Arizona State University. This article is a continuation of the U-Net article, which we will be comparing UNet++ with the original U-Net by Ronneberger et al.
UNet++ aims to improve segmentation accuracy by including Dense block and convolution layers between the encoder and decoder.
Segmentation accuracy is critical for medical images because marginal segmentation errors would lead to unreliable results; thus will be rejected for clinical settings.
Algorithms designed for medical imaging must achieve high performance and accuracy despite having fewer data samples. Acquiring these sample images to train a model can be a resource-consuming process as requires high quality uncompressed and precisely annotated images vetted by professionals.
What is new in UNet++?
Below is an illustration of UNet++ and U-Net architecture.
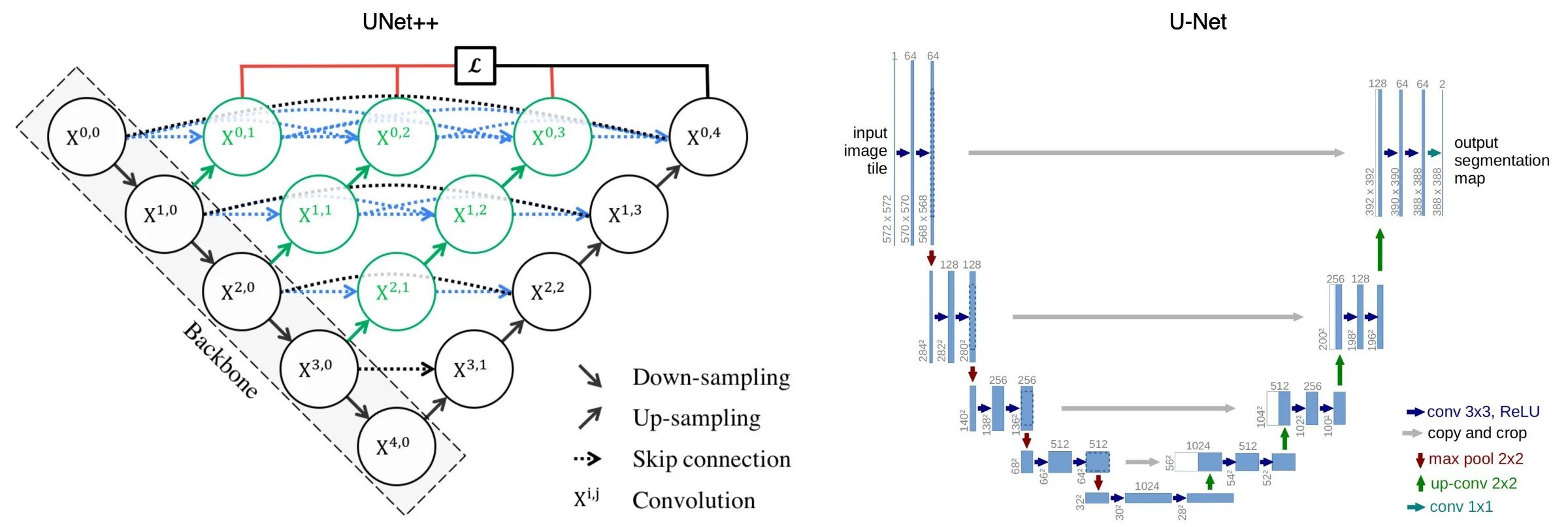
UNet++ have 3 additions to the original U-Net:
- redesigned skip pathways (shown in green)
- dense skip connections (shown in blue)
- deep supervision (shown in red)
Redesigned skip pathways
In UNet++, the redesigned skip pathways (shown in green) have been added to bridge the semantic gap between the encoder and decoder subpaths.
The purpose of these convolutions layers is aimed at reducing the semantic gap between the feature maps of the encoder and decoder subnetworks. As a result, it is possibly a more straightforward optimisation problem for the optimiser to solve.
Skip connections used in U-Net directly connects the feature maps between encoder and decoder, which results in fusing semantically dissimilar feature maps.
However, with UNet++, the output from the previous convolution layer of the same dense block is fused with the corresponding up-sampled output of the lower dense block. This brings the semantic level of the encoded feature closer to that of the feature maps waiting in the decoder; thus optimisation is easier when semantically similar feature maps are received.
All convolutional layers on the skip pathway use kernels of size 3×3.
Dense skip connections
In UNet++, Dense skip connections (shown in blue) has implemented skip pathways between the encoder and decoder. These Dense blocks are inspired by DenseNet with the purpose to improve segmentation accuracy and improves gradient flow.
Dense skip connections ensure that all prior feature maps are accumulated and arrive at the current node because of the dense convolution block along each skip pathway. This generates full resolution feature maps at multiple semantic levels.
Deep supervision
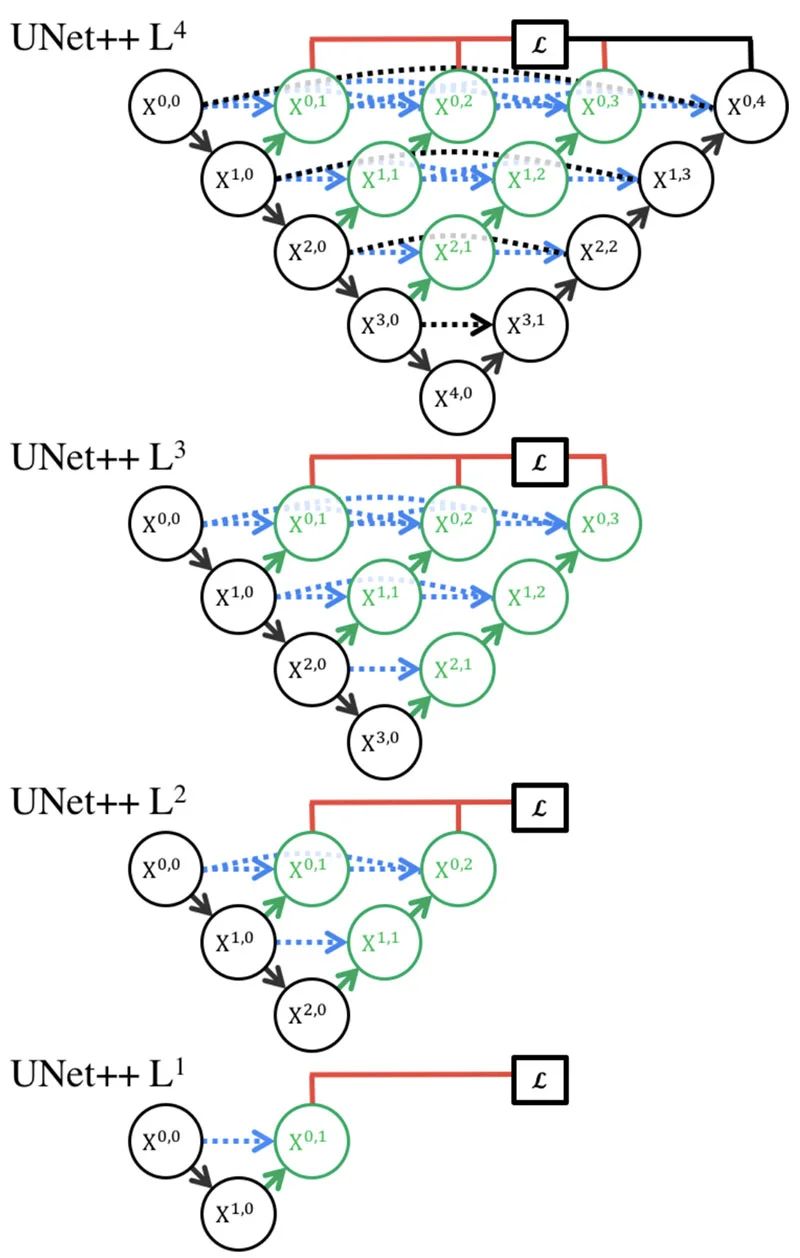
In UNet++, deep supervision (shown in red) are added, so that model can be pruned to adjust the model complexity, to balance between speed (inference time) and performance.
For accurate mode, the output from all segmentation branch is averaged.
For fast mode, the final segmentation map is selected from one of the segmentation branches.
Zhou et al. conducted experiments to determine the best segmentation performance with different levels of pruning. The metrics used are Intersection over Union and inference time.
They experimented on four segmentation tasks: a) cell nuclei, b) colon polyp, c) liver, and d) lung nodule. The results are as follows:
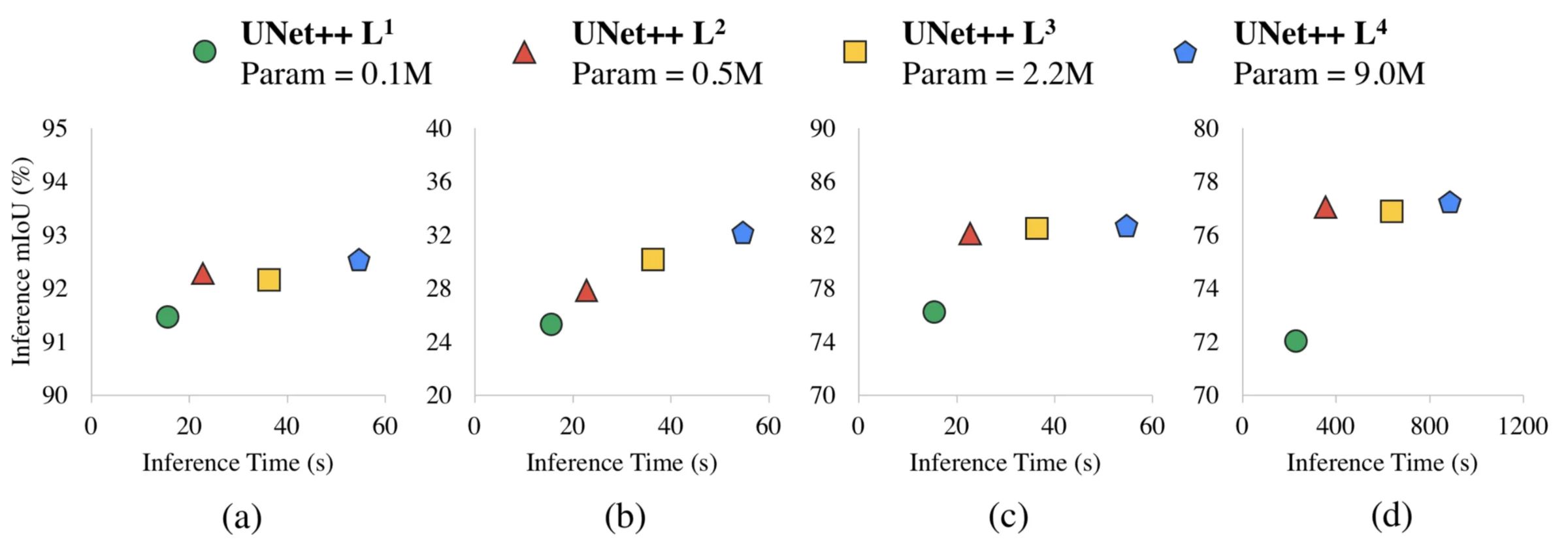
L3 achieved, on average 32.2% reduction in inference time compared to L4 while degrading Intersection over Union marginally.
More aggressive pruning methods such as L1 and L2 can further reduce the inference time but at the cost of significant segmentation performance.
We can tune the number of layers for our use-cases when utilising UNet++.
My experiment on UNet++
My experiment on UNet++ will be using Drishti-GS dataset. The experiment setup and the metrics used will be the same as the U-Net.
The model completed training 36.6M trainable parameters in 27 minutes; each epoch took approximately 32 seconds.
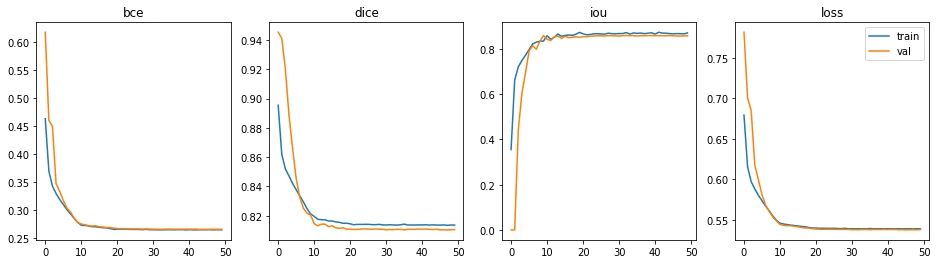
The epoch with the best performance is epoch #45 (out of 50).
- Binary cross-entropy: 0.2650
- Dice coefficient: 0.8104
- Intersection over Union: 0.8580
We are comparing the metrics of the best epoch between U-Net and UNet++.
The test began with the model processing a few unseen samples, to predict optical disc (red) and optical cup (yellow). Here are the test results for UNet++ and U-Net for comparison.
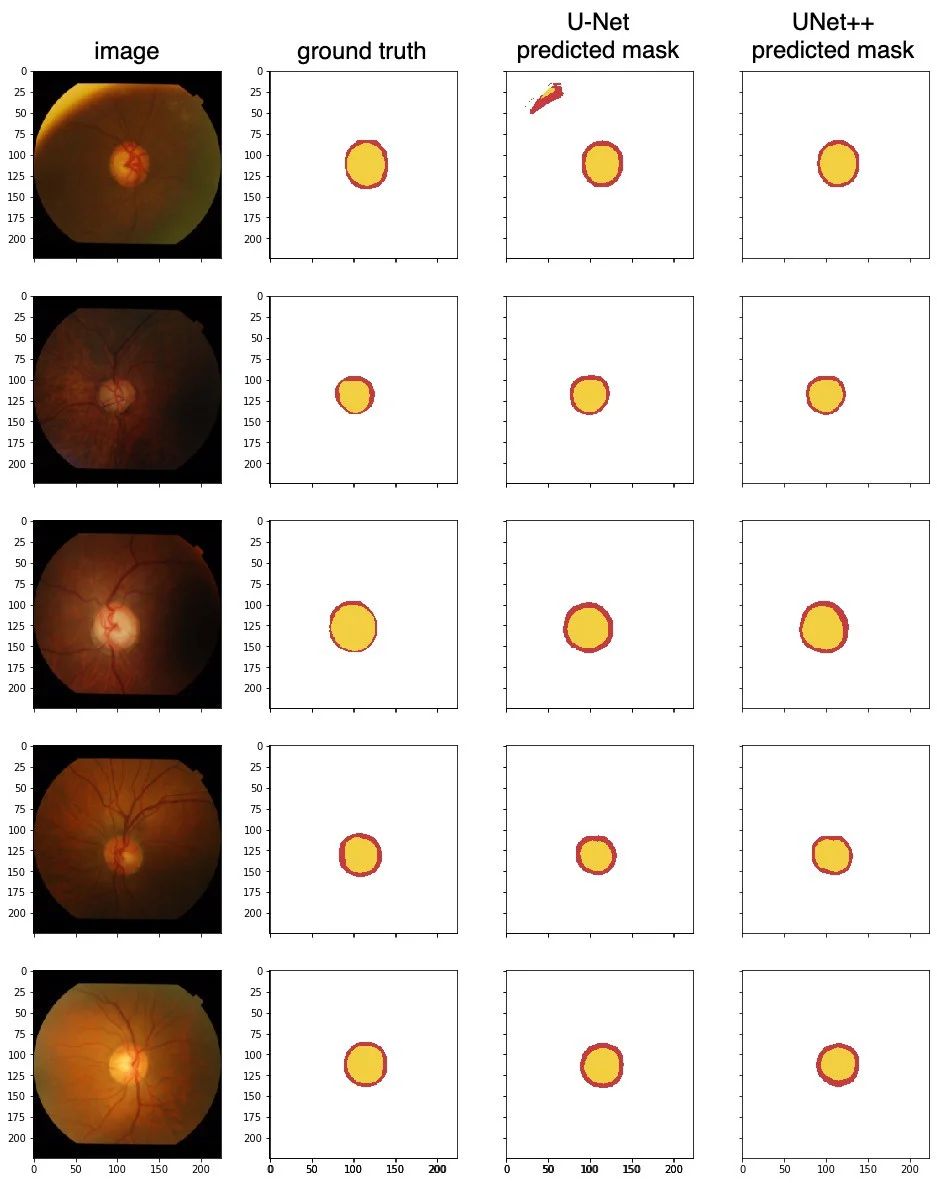
From the metrics table, UNet++ has outperformed U-Net approximately 2% in Intersection over Union. From the qualitative test results, UNet++ has managed to correctly segment the first image, which U-Net did not do so well.
Conclusion
UNet++ aims to improve segmentation accuracy, with a series of nested, dense skip pathways.
Redesigned skip pathways made optimisation easier with the semantically similar feature maps.
Dense skip connections improve segmentation accuracy and improve gradient flow.
Deep supervision allows for model complexity tuning to balance between speed and performance optimisation
Here is the PyTorch code of UNet++ architecture: